The “memory wall” problem was identified more than a decade ago, recognizing that the narrowing gap between speed of CPU and speed of memory meant that processor cores would increasingly sit idle waiting for data. This trend has become even more acute with the advent of many-core processors with a greatly reduced amount of per-core memory. The bottleneck has completely shifted from flops to memory.
Complicating the memory landscape even more are new options in memory subsystems, such as 3D stacked high-bandwidth memories (HBM) to augment traditional DDR DIMMs (figure 1), and Compute Express Link™ (CXL)-attached memory (including storage class memory) to enable a wide variety of memory-sharing scenarios, including accelerators and memory servers (figure 2).
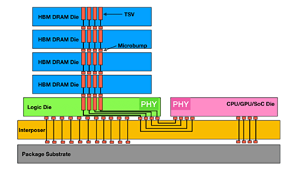
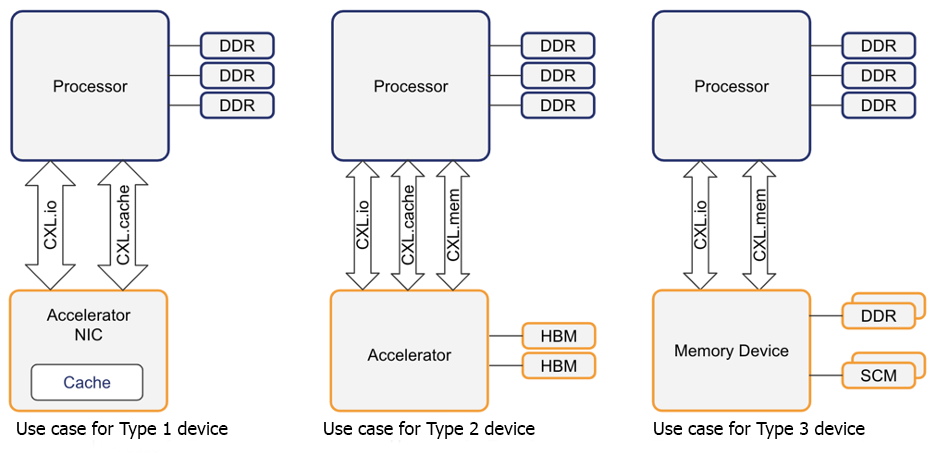
We have developed tools and analyses to study application and system-level memory access patterns. Informed by these studies, we have developed specialized hardware modules and software libraries to optimize memory access while simultaneously increasing memory capacity for data-intensive applications.
Our research program focuses on the following categories of contributions. Expand the accordions for links to software and for publications:
- Studying memory access patterns
- Application-oriented studies and software
- Software libraries
- Hardware blocks (IP)
- Studying memory access patterns
- J. Wahlgren, M. Gokhale, and I. Peng, “Evaluating emerging cxl-enabled memory pooling for HPC systems,” SC22 Workshop on Memory-Centric High Performance Computing (MCHPC). IEEE, November 2022.
- H. Cılasun, C. Macaraeg, I. Peng, A. Sarkar, and M. Gokhale, “FPGA-accelerated simulation of variable latency memory systems,” International Symposium on Memory Systems MEMSYS22. ACM, September 2022.
- I. B. Peng, I. Karlin, M. B. Gokhale, K. Shoga, M. Legendre, and T. Gamblin, “A holistic view of memory utilization on HPC systems: current and future trends,” International Symposium on Memory Systems (MemSys ’21), October 2021.
- I. B. Peng, D. Li, K. Wu, J. Ren, and M. Gokhale, “Demystifying the performance of HPC scientific applications on nvm-based memory systems,” International Parallel and Distributed Processing Symposium, 2020.
- I. B. Peng, M. B. Gokhale, and E. W. Green, “System evaluation of the Intel Optane byte-addressable NVM,” International Symposium on Memory Systems MEMSYS19, ACM, Ed., 2019.
- A. K. Jain, G. S. Lloyd, and M. Gokhale, “Performance assessment of emerging memories through FPGA emulation,” IEEE Micro, vol. 39, no. 1, pp. 8–16, 2019. https://doi.org/10.1109/MM.2018.2877291
- A. K. Jain, G. S. Lloyd, and M. Gokhale, “Microscope on memory: Mpsoc-enabled computer memory system assessments,” in 26th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, FCCM 2018, Boulder, CO, April 29–May 1, 2018, pp. 173–180. https://doi.org/10.1109/FCCM.2018.00035
- J. Landgraf, S. Lloyd, and M. Gokhale, “Combining emulation and simulation to evaluate a near memory key/value lookup accelerator,” https://arxiv.org/abs/2105.06594, 2021.
- Application-oriented studies and software
- M. Shantharam, K. Iwabuchi, P. Cicotti, L. Carrington, M. Gokhale, and R. Pearce, “Performance evaluation of scale-free graph algorithms in low latency non-volatile memory,” Workshop on High Performance Big Data Computing (HPDBC), at IPDPS, May 2017.
- S. K. Ames, D. A. Hysom, G. S. Lloyd, J. E. Allen, and M. Gokhale, “Design and optimization of a metagenomics analysis workflow for nvram,” 28th IEEE International Parallel & Distributed Processing Symposium: Workshop on High Performance Computational Biology (HiCOMB), May 2014.
- Software libraries
- I. B. Peng, M. McFadden, E. Green, K. Iwabuchi, K. Wu, D. Li, R. Pearce, and M. Gokhale, “UMap: Enabling application-driven optimizations for page management,” Workshop on Memory Centric HPC, SC19, 2019.
- I. B. Peng, R. Pearce, and M. Gokhale, “Enabling scalable and extensible memory-mapped datastores in userspace,” Transactions on Parallel and Distributed Systems, 2021.
- K. Iwabuchi, K. Youssef, K. Velusamy, M. Gokhale, and R. Pearce, “Metall: A persistent memory allocator for data-centric analytics,” Parallel Computing, vol. 111, 2022, p. 102905.
- K. Youssef, N. Shah, M. Gokhale, W. Feng, and R. Pearce, “Autopager: Auto-tuning memory-mapped i/o parameters in userspace using Bayesian optimization,” 26th Annual High Performance Embedded Computing (HPEC). IEEE, September 2022.
- Hardware blocks (IP)
- X. Liu, P. Gonzalez-Guerrero, I. B. Peng, R. Minnich, and M. B. Gokhale, “Accelerator integration in a tile-based soc: lessons learned with a hardware floating point compression engine,” SC-W ’23: Proceedings of the SC ’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, 2023.
- M. Barrow, Z. Wu, S. Lloyd, M. Gokhale, H. Patel, and P. Lindstrom, “Zhw: A numerical codec for big data scientific computation,” Field Programmable Technology Conference (FPT ’22), December 2022.
- S. Lloyd and M. Gokhale, “In-memory data rearrangement for irregular, data intensive computing,” IEEE Computer, pp. 18–25, 2015.
- Near-memory data reorganization engine, Patent number 9965187
- S. Lloyd and M. Gokhale, “Near memory key/value lookup acceleration,” International Symposium on Memory Systems MEMSYS17, 2017.
- G. S. Lloyd and M. Gokhale, “Design space exploration of near memory accelerators,” Proceedings of the International Symposium on Memory Systems, MEMSYS 2018, Old Town Alexandria, VA, October 01–04, 2018, 2018, pp. 218–220. https://doi.org/10.1145/3240302.3240428
- L. Zheng, S. Shin, S. Lloyd, and M. Gokhale, “Rram-based tcams for pattern search,” 2016 IEEE Int’l Symposium on Circuits and Systems, May 2016.